使用so-vits-svc进行语音模型训练
Linux AI
训练属于自己的AI模型,使用so-vits-svc进行语音模型训练。用AI声音模型进行推理,让你想要的声音唱你喜欢的歌。
所用项目是so-vits-svc:https://github.com/svc-develop-team/so-vits-svc
训练模型需要遵循官方的使用规范。
模型简介
歌声音色转换模型,通过 SoftVC 内容编码器提取源音频语音特征,与 F0 同时输入 VITS 替换原本的文本输入达到歌声转换的效果。同时,更换声码器为 NSF HiFiGAN 解决断音问题。
使用规约
Warning:请自行解决数据集授权问题,禁止使用非授权数据集进行训练!任何由于使用非授权数据集进行训练造成的问题,需自行承担全部责任和后果!与仓库、仓库维护者、svc develop team 无关!
- 本项目是基于学术交流目的建立,仅供交流与学习使用,并非为生产环境准备。
- 任何发布到视频平台的基于 sovits 制作的视频,都必须要在简介明确指明用于变声器转换的输入源歌声、音频,例如:使用他人发布的视频 / 音频,通过分离的人声作为输入源进行转换的,必须要给出明确的原视频、音乐链接;若使用是自己的人声,或是使用其他歌声合成引擎合成的声音作为输入源进行转换的,也必须在简介加以说明。
- 由输入源造成的侵权问题需自行承担全部责任和一切后果。使用其他商用歌声合成软件作为输入源时,请确保遵守该软件的使用条例,注意,许多歌声合成引擎使用条例中明确指明不可用于输入源进行转换!
- 禁止使用该项目从事违法行为与宗教、政治等活动,该项目维护者坚决抵制上述行为,不同意此条则禁止使用该项目。
- 继续使用视为已同意本仓库 README 所述相关条例,本仓库 README 已进行劝导义务,不对后续可能存在问题负责。
- 如果将此项目用于任何其他企划,请提前联系并告知本仓库作者,十分感谢。
安装wsl2和conda
详细安装可参考之前的文章:Linux基础和wsl安装
为什么用Linux系统来训练AI模型
虽然Windows系统也可以用来训练AI模型,但是Linux系统相对于Windows系统更具优势。Linux的开源环境提供了更好的深度学习框架和工具支持,系统架构在高负载和多任务处理方面更为稳定,灵活的命令行工具和远程访问使用户能够更便捷地管理和监控任务,优秀的资源管理和GPU支持提高了训练效率,可以持续稳定长时间地训练AI模型,达到更好的模型效果。而且Linux环境对于小白更加友好,不容易出现依赖安装失败或者报错等问题。
为什么使用conda
Conda(Anaconda)是一个用于管理和安装python软件包的工具。它让你可以轻松创建、分享、导出和安装项目的环境,以及安装科学计算和机器学习库,简化了依赖管理的过程。 由于不同项目所需的python版本还有pip依赖环境的不同,conda可以很好的管理多版本不同环境依赖的python环境,用于不同AI项目的训练。
AI模型训练对GPU性能要求高,推荐使用6G以上显存的英伟达显卡(如RTX3060)。
在Windows中开启虚拟内存,推荐选择固态硬盘开启16GB以上虚拟内存。具体位置在 此电脑-属性-高级系统设置-高级-性能-高级中的虚拟内存。
环境依赖准备
Python
在进行测试后,我们认为
Python 3.8.9能够稳定地运行该项目.
conda create --name python3.8 python=3.8 #创建python3.8的conda环境
conda activate python3.8 #激活conda环境
CUDA
在命令行中输入nvidia-smi显示显卡信息。
在官网安装cuda-toolkit,选择Linux对应Linux系统版本,选择network版本,然后按照命令一句句执行安装。若显卡cuda版本过低,需要安装其他版本的https://developer.nvidia.com/cuda-toolkit-archive在这里选择安装对应版本。
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-3
Pytorch
根据对应的cuda版本选择安装Pytorch版本,https://pytorch.org/get-started/locally/,选择对应版本安装。注意,高版本的cuda能兼容低版本的pytorch。
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
测试环境
python
# 回车运行
import torch
# 回车运行
print(torch.__version__)
# 回车运行
print(torch.cuda.is_available())
# 回车运行,显示true代表版本匹配
配置项目
使用
git clone https://github.com/svc-develop-team/so-vits-svc.git克隆项目到本地。或者直接在项目页面download zip,下载源码再解压放置到特定文件夹。进入项目文件夹
cd so-vits-svc。下载项目所需的pip依赖
pip install -r requirements.txt。根据官方文档,进行模型文件预下载、数据集准备、数据预处理、训练等。
预下载模型文件
必须项
以下编码器需要选择一个使用
1. 若使用 contentvec 作为声音编码器(推荐)
vec768l12与vec256l9 需要该编码器
- contentvec :checkpoint_best_legacy_500.pt
- 放在
pretrain目录下
- 放在
或者下载下面的 ContentVec,大小只有 199MB,但效果相同:
- contentvec :hubert_base.pt
- 将文件名改为
checkpoint_best_legacy_500.pt后,放在pretrain目录下
- 将文件名改为
# contentvec
wget -P pretrain/ http://obs.cstcloud.cn/share/obs/sankagenkeshi/checkpoint_best_legacy_500.pt
# 也可手动下载放在pretrain目录
2. 若使用 hubertsoft 作为声音编码器
- soft vc hubert:hubert-soft-0d54a1f4.pt
- 放在
pretrain目录下
- 放在
3. 若使用 Whisper-ppg 作为声音编码器
- 下载模型 medium.pt, 该模型适配
whisper-ppg - 下载模型 large-v2.pt, 该模型适配
whisper-ppg-large- 放在
pretrain目录下
- 放在
4. 若使用 cnhubertlarge 作为声音编码器
- 下载模型 chinese-hubert-large-fairseq-ckpt.pt
- 放在
pretrain目录下
- 放在
5. 若使用 dphubert 作为声音编码器
- 下载模型 DPHuBERT-sp0.75.pth
- 放在
pretrain目录下
- 放在
6. 若使用 OnnxHubert/ContentVec 作为声音编码器
- 下载模型 MoeSS-SUBModel
- 放在
pretrain目录下
- 放在
编码器列表
- "vec768l12"
- "vec256l9"
- "vec256l9-onnx"
- "vec256l12-onnx"
- "vec768l9-onnx"
- "vec768l12-onnx"
- "hubertsoft-onnx"
- "hubertsoft"
- "whisper-ppg"
- "cnhubertlarge"
- "dphubert"
- "whisper-ppg-large"
可选项(强烈建议使用)
预训练底模文件:
G_0.pthD_0.pth- 放在
logs/44k目录下
- 放在
扩散模型预训练底模文件:
model_0.pt- 放在
logs/44k/diffusion目录下
- 放在
扩散模型引用了DDSP-SVC的 Diffusion Model,底模与DDSP-SVC的扩散模型底模通用,可以去DDSP-SVC获取扩散模型的底模
虽然底模一般不会引起什么版权问题,但还是请注意一下,比如事先询问作者,又或者作者在模型描述中明确写明了可行的用途。
数据集准备
仅需要以以下文件结构将数据集放入 dataset_raw 目录即可。
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
对于每一个音频文件的名称并没有格式的限制(000001.wav~999999.wav之类的命名方式也是合法的),不过文件类型必须是wav。
可以自定义说话人名称
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
🛠️ 数据预处理
0. 音频切片
将音频切片至5s - 15s, 稍微长点也无伤大雅,实在太长可能会导致训练中途甚至预处理就爆显存
可以使用 audio-slicer-GUI、audio-slicer-CLI
一般情况下只需调整其中的Minimum Interval,普通陈述素材通常保持默认即可,歌唱素材可以调整至100甚至50
切完之后手动删除过长过短的音频
如果你使用 Whisper-ppg 声音编码器进行训练,所有的切片长度必须小于 30s
1. 重采样至 44100Hz 单声道
python resample.py
注意
虽然本项目拥有重采样、转换单声道与响度匹配的脚本 resample.py,但是默认的响度匹配是匹配到 0db。这可能会造成音质的受损。而 python 的响度匹配包 pyloudnorm 无法对电平进行压限,这会导致爆音。所以建议可以考虑使用专业声音处理软件如adobe audition等软件做响度匹配处理。若已经使用其他软件做响度匹配,可以在运行上述命令时添加--skip_loudnorm跳过响度匹配步骤。如:
python resample.py --skip_loudnorm
2. 自动划分训练集、验证集,以及自动生成配置文件
python preprocess_flist_config.py --speech_encoder vec768l12
speech_encoder 拥有以下选择
vec768l12
vec256l9
hubertsoft
whisper-ppg
whisper-ppg-large
cnhubertlarge
dphubert
wavlmbase+
如果省略 speech_encoder 参数,默认值为 vec768l12
使用响度嵌入
若使用响度嵌入,需要增加--vol_aug参数,比如:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug
使用后训练出的模型将匹配到输入源响度,否则为训练集响度。
此时可以在生成的 config.json 与 diffusion.yaml 修改部分参数
config.json
keep_ckpts:训练时保留最后几个模型,0为保留所有,默认只保留最后3个all_in_mem:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 远大于 数据集体积时可以启用batch_size:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可vocoder_name: 选择一种声码器,默认为nsf-hifigan.
diffusion.yaml
cache_all_data:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 远大于 数据集体积时可以启用duration:训练时音频切片时长,可根据显存大小调整,注意,该值必须小于训练集内音频的最短时间!batch_size:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可timesteps: 扩散模型总步数,默认为 1000.k_step_max: 训练时可仅训练k_step_max步扩散以节约训练时间,注意,该值必须小于timesteps,0 为训练整个扩散模型,注意,如果不训练整个扩散模型将无法使用仅扩散模型推理!
声码器列表
nsf-hifigan
nsf-snake-hifigan
3. 生成 hubert 与 f0
python preprocess_hubert_f0.py --f0_predictor dio
f0_predictor 拥有以下选择
crepe
dio
pm
harvest
rmvpe
fcpe
如果训练集过于嘈杂,请使用 crepe 处理 f0
如果省略 f0_predictor 参数,默认值为 rmvpe
尚若需要浅扩散功能(可选),需要增加--use_diff 参数,比如
python preprocess_hubert_f0.py --f0_predictor dio --use_diff
加速预处理 如若您的数据集比较大,可以尝试添加--num_processes参数:
python preprocess_hubert_f0.py --f0_predictor dio --use_diff --num_processes 8
所有的Workers会被自动分配到多个线程上
执行完以上步骤后 dataset 目录便是预处理完成的数据,可以删除 dataset_raw 文件夹了
🏋️ 训练
主模型训练
python train.py -c configs/config.json -m 44k
扩散模型(可选)
尚若需要浅扩散功能,需要训练扩散模型,扩散模型训练方法为:
python train_diff.py -c configs/diffusion.yaml
模型训练结束后,模型文件保存在logs/44k目录下,扩散模型在logs/44k/diffusion下
如果前面的效果已经满意,或者没看明白下面在讲啥,那后面的内容都可以忽略,不影响模型使用(这些可选项影响比较小,可能在某些特定数据上有点效果,但大部分情况似乎都感知不太明显)
模型效果增强
自动 f0 预测
4.0 模型训练过程会训练一个 f0 预测器,对于语音转换可以开启自动音高预测,如果效果不好也可以使用手动的,但转换歌声时请不要启用此功能!!!会严重跑调!!
- 在 inference_main 中设置 auto_predict_f0 为 true 即可
聚类音色泄漏控制
介绍:聚类方案可以减小音色泄漏,使得模型训练出来更像目标的音色(但其实不是特别明显),但是单纯的聚类方案会降低模型的咬字(会口齿不清)(这个很明显),本模型采用了融合的方式,可以线性控制聚类方案与非聚类方案的占比,也就是可以手动在"像目标音色" 和 "咬字清晰" 之间调整比例,找到合适的折中点
使用聚类前面的已有步骤不用进行任何的变动,只需要额外训练一个聚类模型,虽然效果比较有限,但训练成本也比较低
- 训练过程:
- 使用 cpu 性能较好的机器训练,据我的经验在腾讯云 6 核 cpu 训练每个 speaker 需要约 4 分钟即可完成训练
- 执行
python cluster/train_cluster.py,模型的输出会在logs/44k/kmeans_10000.pt - 聚类模型目前可以使用 gpu 进行训练,执行
python cluster/train_cluster.py --gpu
# CPU
python cluster/train_cluster.py
# GPU
python cluster/train_cluster.py --gpu
- 推理过程:
inference_main.py中指定cluster_model_pathinference_main.py中指定cluster_infer_ratio,0为完全不使用聚类,1为只使用聚类,通常设置0.5即可
特征检索
介绍:跟聚类方案一样可以减小音色泄漏,咬字比聚类稍好,但会降低推理速度,采用了融合的方式,可以线性控制特征检索与非特征检索的占比,
- 训练过程: 首先需要在生成 hubert 与 f0 后执行:
python train_index.py -c configs/config.json
模型的输出会在logs/44k/feature_and_index.pkl
- 推理过程:
- 需要首先制定
--feature_retrieval,此时聚类方案会自动切换到特征检索方案 inference_main.py中指定cluster_model_path为模型输出文件inference_main.py中指定cluster_infer_ratio,0为完全不使用特征检索,1为只使用特征检索,通常设置0.5即可
- 需要首先制定
🤖 推理
# 例
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -n "君の知らない物語-src.wav" -t 0 -s "nen"
必填项部分:
-m|--model_path:模型路径-c|--config_path:配置文件路径-n|--clean_names:wav 文件名列表,放在 raw 文件夹下-t|--trans:音高调整,支持正负(半音)-s|--spk_list:合成目标说话人名称-cl|--clip:音频强制切片,默认 0 为自动切片,单位为秒/s
可选项部分:部分具体见下一节
-lg|--linear_gradient:两段音频切片的交叉淡入长度,如果强制切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值 0,单位为秒-f0p|--f0_predictor:选择 F0 预测器,可选择 crepe,pm,dio,harvest,rmvpe,fcpe, 默认为 pm(注意:crepe 为原 F0 使用均值滤波器)-a|--auto_predict_f0:语音转换自动预测音高,转换歌声时不要打开这个会严重跑调-cm|--cluster_model_path:聚类模型或特征检索索引路径,留空则自动设为各方案模型的默认路径,如果没有训练聚类或特征检索则随便填-cr|--cluster_infer_ratio:聚类方案或特征检索占比,范围 0-1,若没有训练聚类模型或特征检索则默认 0 即可-eh|--enhance:是否使用 NSF_HIFIGAN 增强器,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭-shd|--shallow_diffusion:是否使用浅层扩散,使用后可解决一部分电音问题,默认关闭,该选项打开时,NSF_HIFIGAN 增强器将会被禁止-usm|--use_spk_mix:是否使用角色融合/动态声线融合-lea|--loudness_envelope_adjustment:输入源响度包络替换输出响度包络融合比例,越靠近 1 越使用输出响度包络-fr|--feature_retrieval:是否使用特征检索,如果使用聚类模型将被禁用,且 cm 与 cr 参数将会变成特征检索的索引路径与混合比例
浅扩散设置:
-dm|--diffusion_model_path:扩散模型路径-dc|--diffusion_config_path:扩散模型配置文件路径-ks|--k_step:扩散步数,越大越接近扩散模型的结果,默认 100-od|--only_diffusion:纯扩散模式,该模式不会加载 sovits 模型,以扩散模型推理-se|--second_encoding:二次编码,浅扩散前会对原始音频进行二次编码,玄学选项,有时候效果好,有时候效果差
注意!
如果使用whisper-ppg 声音编码器进行推理,需要将--clip设置为 25,-lg设置为 1。否则将无法正常推理。
使用webUI推理
python webUI.py
浏览器打开推理的webui界面,上传模型和config文件(必须项),扩散模型和配置可选上传,然后加载模型。使用文本转语音功能最好开启f0预测。
人声伴奏分离
使用工具**ULTIMATE VOCAL REMOVER**进行纯净的人声分离,可用于人声训练集,或者用于歌曲干声推理工程。
GUI地址:https://github.com/Anjok07/ultimatevocalremovergui。
提取人声推荐使用5_HP-Karaoke-UVR这个模型,分离得比较干净。
提取伴奏推荐使用7_HP2-UVR。
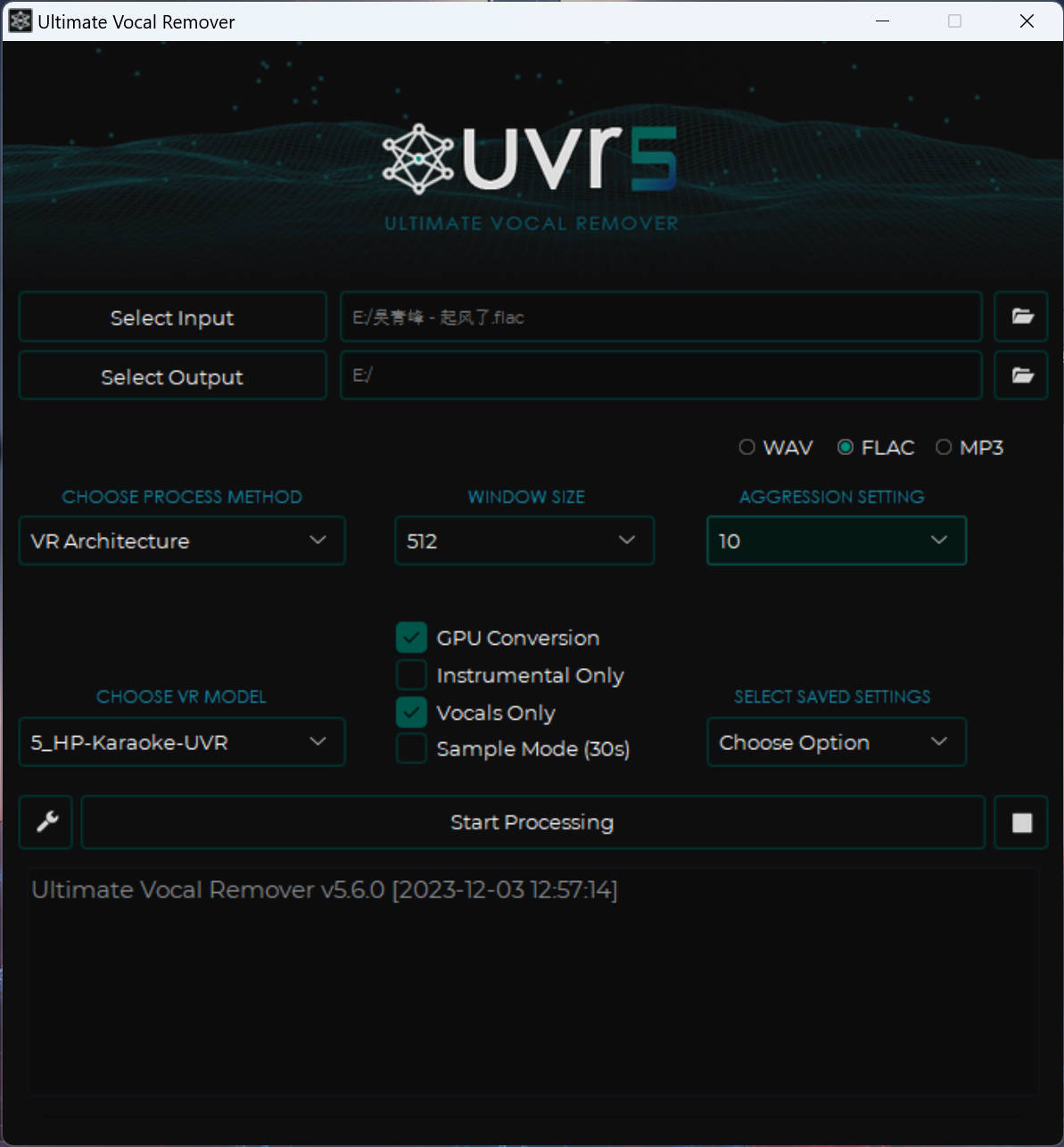
选择输入文件和输出文件夹
勾选CPU Conversion,Instrumental是提取伴奏,Vocals是提取人声。
选择模型。
如果没有模型,点击扳手图标,Download Center下载对应模型。
下载不了的话,可以点Manual Download,从浏览器下载,放到models文件夹里即可。
点Start Processing开始分离。根据你GPU的性能来决定进程速度。
继续训练
如果觉得训练的步数过少,可以选择继续训练,把训练文件: G_20000.pth D_20000.pth放在logs/44k目录下,然后执行训练代码就可以继续训练。
如果想要训练其他的模型,首先删除之前的项目文件夹,重新克隆git仓库项目,由于环境已经配置好,不需要再重新配置环境,进入conda的python环境,导入训练集按照上方配置项目重新进行训练即可。
- 模型简介
- 使用规约
- 安装wsl2和conda
- 为什么用Linux系统来训练AI模型
- 为什么使用conda
- 环境依赖准备
- Python
- CUDA
- Pytorch
- 测试环境
- 配置项目
- 预下载模型文件
- 必须项
- 1. 若使用 contentvec 作为声音编码器(推荐)
- 2. 若使用 hubertsoft 作为声音编码器
- 3. 若使用 Whisper-ppg 作为声音编码器
- 4. 若使用 cnhubertlarge 作为声音编码器
- 5. 若使用 dphubert 作为声音编码器
- 6. 若使用 OnnxHubert/ContentVec 作为声音编码器
- 编码器列表
- 可选项(强烈建议使用)
- 数据集准备
- 🛠️ 数据预处理
- 0. 音频切片
- 1. 重采样至 44100Hz 单声道
- 注意
- 2. 自动划分训练集、验证集,以及自动生成配置文件
- 此时可以在生成的 config.json 与 diffusion.yaml 修改部分参数
- config.json
- diffusion.yaml
- 声码器列表
- 3. 生成 hubert 与 f0
- 🏋️ 训练
- 主模型训练
- 扩散模型(可选)
- 模型效果增强
- 自动 f0 预测
- 聚类音色泄漏控制
- 特征检索
- 🤖 推理
- 注意!
- 使用webUI推理
- 人声伴奏分离
- 继续训练